2021.07.吴月明3.IntDroid:基于API亲密度分析的Android恶意软件检测
ccfa
IntDroid: Android Malware Detection Based on API Intimacy Analysis
IntDroid:基于API亲密度分析的Android恶意软件检测

Android恶意软件检测的新方法
Android作为最受欢迎的移动操作系统,吸引了全球数百万用户。与此同时,近年来新的Android恶意软件实例的数量呈指数级增长。一方面,现有的Android恶意软件检测系统已经证明,将程序语义提炼为图形表示,并通过进行图匹配来检测恶意程序,能够在检测Android恶意软件时达到高准确率。然而,这些传统的基于图的方法总是需要进行昂贵的程序分析,并且在恶意软件检测的可扩展性上表现不佳。另一方面,由于社交网络分析的高可扩展性,它已被应用于完成大规模的恶意软件检测。然而,基于社交网络分析的方法只考虑简单的语义信息(即中心性),用于实现市场范围内的移动恶意软件扫描,这可能在良性应用表现出与恶意软件相似的行为时限制检测的有效性。
在本文中,我们旨在将传统基于图的方法的高准确性与基于社交网络分析的方法的高可扩展性结合起来,用于Android恶意软件的检测。我们不使用传统的重量级静态分析,而是将应用的函数调用图视为复杂的社交网络,并应用基于社交网络的中心性分析来挖掘调用图中的中心节点。获取中心节点后,计算敏感API调用与中心节点之间的平均亲密度,以表示图的语义特征。我们在一个名为IntDroid的工具中实现了我们的方法,并在一个包含3,988个良性样本和4,265个恶意样本的数据集上进行评估。实验结果显示,IntDroid能够在保持99.1%的真阳性率的同时,检测Android恶意软件的F-measure达到97.1%。尽管其可扩展性不如基于社交网络分析的方法(即MalScan),与传统的基于图的方法相比,IntDroid的速度快了六倍以上。此外,在从GooglePlay市场收集的应用程序语料库中,IntDroid能够识别出28个能够规避现有工具检测的零日恶意软件,其中一个已被超过一千万用户下载并安装。这个应用还被VirusTotal中的六个反病毒扫描器标记为恶意软件,其中一个是赛门铁克移动洞察。
CCS概念
- 安全与隐私 → 恶意软件及其缓解
关键词和短语
- Android恶意软件,API亲密度,社交网络,中心性
1 引言
在2018年第二季度,谷歌的Android系统进一步扩大了其相对于苹果iOS的领先优势,占据了88%的市场份额,而iOS仅占11.9%[4]。Android设备和应用程序(apps)的爆炸性增长也刺激了Android恶意软件的增长。全球数以百万计的Android用户从各种应用市场安装了应用程序。截至2018年第三季度末,新增恶意应用的数量较上年同期增长超过40%[3]。相应地,Android恶意软件的激增也引发了开发自动检测恶意软件方法的强烈热情。
总的来说,现有的移动恶意软件检测方法可以分为基于语法的方法[9, 12, 36, 46, 50, 53, 60]和基于语义的方法[10, 16, 24, 28, 43, 56-58]。在基于语法的技术中,例如,一些方法[46, 53]关注应用程序请求的权限并建立恶意软件检测模型。然而,恶意软件可以在不需要任何权限的情况下执行恶意活动[29]。此外,良性应用可能会请求超出必要的权限,这也会导致较高的误报率[20]。为了解决这个问题,Drebin[12]使用了广泛的静态分析来获取尽可能多的特征,这些特征包括权限和API调用。然而,由于缺乏程序行为的结构和上下文信息,它很容易被混淆技术规避。
为了克服这一挑战,一些系统提出将应用程序的程序语义提炼为图形表示,并通过图形匹配来检测恶意软件。实证研究[24, 28, 58]表明,这些基于图的技术在Android恶意软件检测方面具有很高的有效性。然而,图形匹配通常非常耗时,因为一个图通常包含数千个节点。例如,DroidSIFT[58]和Apposcopy[24]对一个应用程序的平均分析时间分别为175.8秒和275秒。换句话说,这些基于图的技术在检测移动恶意软件时存在可扩展性低的问题。
为了实现更具可扩展性的恶意软件检测,一种基于抽象的方法被提出,即MaMaDroid[43],它利用从调用图获得的抽象序列来模拟应用程序的行为。具体来说,它建立了一个马尔可夫链模型来表示方法调用之间的转换,这些马尔可夫链代表应用程序执行的多个成对调用关系,并用于提取特征以完成分类。MaMaDroid中的方法调用抽象和马尔可夫链建模可以在检测移动恶意软件时实现稳健性和可扩展性。
然而,一些设计选择可能会限制MaMaDroid的有效性。首先,一阶马尔可夫链(即成对调用)无法完全反映方法调用之间的依赖关系,因此该方法缺乏将某些恶意应用与良性应用区分开来的关键信息。此外,粗粒度信息(即包级别信息而不是方法级别信息)可能无法准确区分良性应用和恶意软件。例如,android.telephony.TelephonyManager.getDeviceId()和android.telephony.SmsManager.sendTextMessage()都被抽象在android.telephony包中,而它们的用途和敏感程度完全不同。这些设计选择是可以理解的,因为使用整图分析(而不是仅考虑成对调用)和更细粒度的信息(即方法级别信息)可能会产生更高的成本,从而使大规模恶意软件扫描变得不可行。
为了解决上述问题,我们在之前的工作[54]中提出了MalScan来完成市场范围的移动恶意软件扫描。MalScan将应用程序的函数调用图视为复杂的社交网络,并对敏感API调用应用社交网络中心性分析来表示图形语义以进行恶意软件检测。然而,仅使用敏感API调用的中心性来进行恶意软件检测可能会在良性应用通过调用敏感API表现出与恶意软件类似行为时导致一些误报。在这种情况下,良性应用中某些敏感API调用的中心性可能与某些恶意软件中的几乎相同。例如,一些社交应用(如抖音)需要访问用户的位置以呈现特定位置的新闻或视频,并读取用户的通讯录以推荐新朋友。在这种情况下,敏感API调用LocationManager.getLastLocation()的中心性可能与某些恶意软件几乎相同,这可能会导致误报。
总之,一方面,传统的基于图分析的方法[24, 28, 43, 58]由于考虑了不同类型的程序语义,可以在Android恶意软件检测方面取得高效性。然而,这些方法的效率并不理想,因为一个图通常包含数千个节点,导致恶意软件检测的可扩展性较低。另一方面,基于社交网络分析的方法[54]由于社交网络分析的高可扩展性,能够完成市场范围的Android恶意软件扫描。然而,MalScan[54]仅考虑敏感API调用的中心性,这种简单的考虑可能会在应用程序通过调用敏感API表现出与恶意软件类似行为时限制检测效果。
因此,我们提出一个研究问题:是否有办法将传统基于图分析方法的高效性与基于社交网络分析方法的高可扩展性相结合,用于Android恶意软件检测?
在本文中,我们旨在解决上述研究问题。为了实现传统基于图分析方法和基于社交网络分析方法之间的结合和平衡,我们首先利用社交网络中心性分析对整个图进行挖掘,找出最重要的节点(即中心节点)。然后应用传统图分析来计算这些节点与敏感API调用之间的亲密度作为语义特征,这些特征提供了更有效的图细节来区分恶意软件和良性应用。
我们的关键洞察来源于对日常生活社交网络的观察。我们发现,一个人在不同的社交网络中可能会表现出与相应社交网络中心人物之间不同的亲密度(即通信频率)。在恶意软件检测的背景下,由于良性应用(例如,提供实用功能)和恶意软件(例如,最大化利润,延长生命周期)[57]的固有目标不同,一个API方法可能在不同的函数调用网络中与中心节点有不同的通信频率。
具体来说,为了维持程序语义,我们首先基于静态分析提取应用程序的函数调用图。给定一个调用图,我们然后应用中心性分析来发掘图中的中心节点。中心性的概念最初是在社交网络分析中提出的,其原始目标是量化网络中顶点的重要性。我们利用方法调用中心性的分析结果来找到具有高中心性的节点(即中心节点)。此外,由于恶意软件总是调用一些敏感API来执行恶意活动,我们关注这些API调用。因此,在获得图中的中心节点后,我们进行亲密度分析来计算敏感API调用和中心节点之间的平均亲密度。我们对调用图中两个节点之间亲密度的定义包括两个影响因素:(1)可达路径的数量和(2)平均路径距离。换句话说,可达路径数量越多,平均路径距离越短,两个节点之间的亲密度就越高。这些计算出的亲密度被用作特征,并输入机器学习分类器以训练模型并对新给定的特征向量进行分类。
我们实现了一个原型系统IntDroid,并使用3,988个良性样本和4,265个恶意样本进行评估。实验结果表明,IntDroid能够以97.1%的F-measure检测Android恶意软件,同时真阳性率能够保持在99.1%。在可扩展性方面,由于亲密度分析的过程,IntDroid不如基于社交网络分析的方法(即MalScan[54])快,但与最先进的传统基于图的方法(即MaMaDroid[43])相比,IntDroid的时间开销减少了六倍多。
我们还检验了IntDroid在检测零日恶意软件方面的能力。具体来说,在从GooglePlay市场收集的应用程序语料库中,IntDroid能够识别28个可以逃避现有工具检测的零日恶意软件,其中一个已被超过一千万用户下载和安装。这个应用程序也被VirusTotal中的六个防病毒扫描器标记为恶意软件,其中之一是赛门铁克移动洞察。
总之,本文做出了以下贡献:
-
我们提出了一种新方法,通过分析函数调用图中敏感API调用与中心节点之间的亲密度来检测Android恶意软件。
-
我们设计并实现了一个原型系统IntDroid,将传统基于图分析方法的高效性与基于社交网络分析方法的高可扩展性相结合,以检测Android恶意软件。
-
我们使用3,988个良性样本和4,265个恶意样本进行评估。实验结果表明,IntDroid能够以97.1%的F-measure和99.1%的真阳性率检测Android恶意软件。此外,与传统的基于图的方法相比,IntDroid比MaMaDroid[43]快六倍多。
文章组织。本文的其余部分组织如下。第2节介绍我们的动机。第3节展示定义。第4节介绍我们的系统。第5节报告实验结果。第6节介绍与MalScan的广泛比较。第7节讨论未来工作和局限性。第8节描述相关工作。第9节总结本文。
2 动机
为了理解关键洞察,我们检查了一个良性应用和一个恶意应用的API调用网络。这个良性应用是一个为Android提供更安全体验的移动安全应用,而恶意应用则允许追踪丢失的手机。我们分析了这两个应用的API调用并创建了函数调用图。这些应用的函数调用图可以被视为API调用网络。节点代表函数,边代表它们之间的通信。边的方向用于帮助区分图中的调用者和被调用者。例如,在图1中,从节点MainActivity.onResume()到节点PreferenceManager.getDefaultSharedPreferences()的边表示从函数MainActivity.onResume()到函数PreferenceManager.getDefaultSharedPreferences()的调用路径。
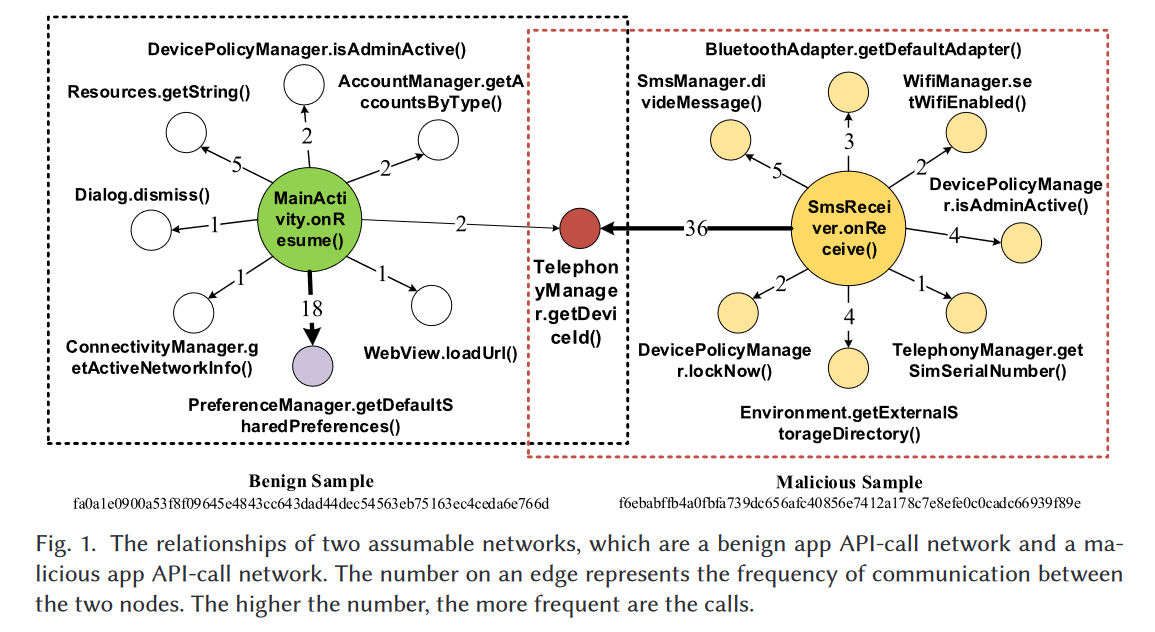
对于每个API调用网络,我们基于节点度选择一个中心节点。如图1所示,良性应用网络以节点MainActivity.onResume()为中心,向外连接到PreferenceManager.AccountManager()等节点。恶意应用网络以节点SmsReceiver.onReceive()为中心,向外连接到TelephonyManager.DevicePolicyManager()等节点。函数MainActivity.onResume()和SmsReceiver.onReceive()是生命周期方法,因此它们具有高度。应用开发者重写这些函数以进行特定实现,这通常涉及对其他API的多次调用。这些API调用中有许多属于敏感方法[13],在这种情况下,我们将它们称为敏感API调用。

图1中边的权重表示两个节点之间的通信频率。权重越高,从中心节点到API的调用就越频繁。表1分别展示了图1中节点PreferenceManager.getDefaultSharedPreferences()、TelephonyManager.getDeviceId()与MainActivity.onResume()、SmsReceiver.onReceive()之间的通信频率。如果我们将亲密度定义为两个函数之间的通信频率,那么从图1和表1中呈现的结果可以看出,由于PreferenceManager.getDefaultSharedPreferences()和TelephonyManager.getDeviceId()的不同目标,它们与中心节点之间的亲密度是不同的。
基于这个观察,我们提出一个问题:恶意应用中敏感API调用与中心节点之间的亲密度是否与良性应用中敏感API调用与中心节点之间的亲密度不同?
为了回答这个问题,我们从AndroZoo[11]中随机选择了500个良性应用和500个恶意应用。然后基于静态分析提取函数调用图。给定一个调用图,我们选择度值排名前1%的节点作为调用图中的中心节点。在获得调用图中的中心节点后,我们计算敏感API调用和中心节点之间的亲密度。如前所述,我们简单地将亲密度定义为社交网络中两个人之间的通信频率。因此,为了更精确地定义函数调用图中两个节点之间的亲密度,我们选择了以下两个影响因素:(1)可达路径的数量和(2)平均路径距离。换句话说,可达路径数量越多,平均路径距离越短,两个节点之间的亲密度就越高。第4节将展示一个更详细的真实世界示例。
我们从安全敏感方法列表[13]中选择了前缀为android.telephony.TelephonyManager.get的API调用作为测试对象。在计算调用图中敏感API调用与中心节点之间的所有亲密度后,我们收集这些亲密度的平均值。事实上,由于我们随机选择的数据集规模较小,仅包含500个良性应用和500个恶意应用,一些敏感API调用并未出现在这些应用中。在这种情况下,平均亲密度值都为零,因此,我们只考虑同时被良性应用和恶意应用调用的API。最终,PScout[13]中前缀为android.telephony.TelephonyManager.get的满足条件的API调用总数为14个。由于页面限制,我们只展示部分结果。
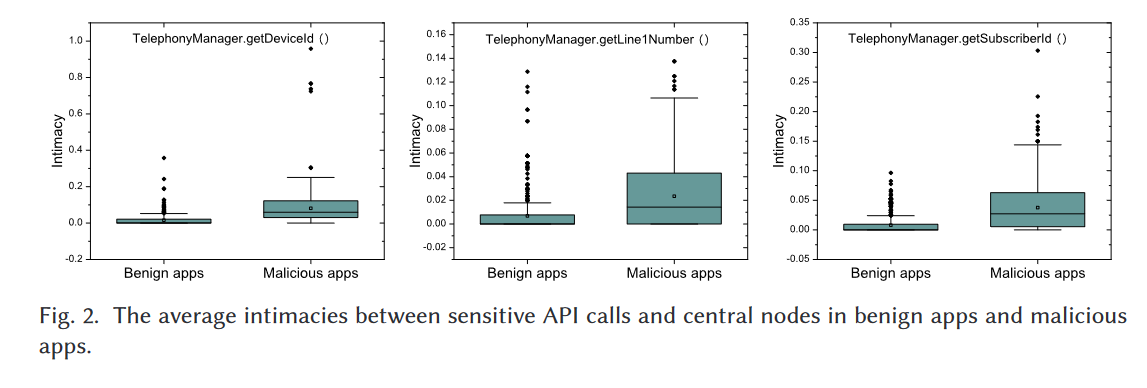
图2显示了三个敏感API调用的平均亲密度分布:(1)TelephonyManager.getDeviceID()可以获取手机的国际移动设备识别码(IMEI),(2)TelephonyManager.getLine1Number()可以获取手机号码,(3)TelephonyManager.getSubscriberld()可以获取手机的国际移动用户识别码(IMSI)。图2中的结果表明,良性应用和恶意应用中敏感API调用与调用图中中心节点之间的平均亲密度存在差异。
为了获得更确定的结果,我们首先进行Shapiro-Wilk测试[51]来检查平均亲密度是否呈正态分布。在获得测试结果后,我们发现这些敏感API调用与中心节点之间的平均亲密度不符合正态分布。因此,我们采用非参数检验(即Mann-Whitney U检验[41]),该检验对正态性偏差具有鲁棒性。Mann-Whitney U检验的零假设是两个总体具有相同的均值,备择假设是两个总体的均值不同。第一类错误率或显著性水平是在零假设为真时拒绝零假设的概率。如果计算出的p值小于预先确定的阈值α(称为显著性水平),则拒绝零假设。通常,显著性水平设置为0.05,这意味着可以接受5%的概率错误地拒绝真实的零假设。
| API调用 | P值 |
|---|---|
| TelephonyManager.getSimOperator() | 0.054473 |
| TelephonyManager.getSimState() | 0.014292 |
| TelephonyManager.getNetworkType() | 0.004563 |
| TelephonyManager.getNetworkCountryIso() | 0.000743 |
| TelephonyManager.getSimOperatorName() | 3.02E-05 |
| TelephonyManager.getPhoneType() | 6.81E-18 |
| TelephonyManager.getSimSerialNumber() | 8.43E-29 |
| TelephonyManager.getLine1Number() | 5.36E-31 |
| TelephonyManager.getDeviceID() | 3.59E-36 |
| TelephonyManager.getSimCountryIso() | 6.09E-47 |
| TelephonyManager.getNetworkOperator() | 1.36E-55 |
| TelephonyManager.getSubscriberId() | 5.43E-63 |
| TelephonyManager.getCellLocation() | 9.75E-97 |
| TelephonyManager.getNetworkOperatorName() | 5.6E-118 |
我们使用Mann-Whitney U检验来实验这些API调用,以检验良性应用和恶意应用之间API亲密度的差异。表2展示了14个前缀为android.telephony.TelephonyManager.get的API调用在良性应用和恶意应用之间平均亲密度的p值。如表2所示,我们可以看到大多数p值小于0.05。换句话说,对于表2中的大多数API调用,我们可以拒绝零假设。因此,基于这个观察,我们提出并开发了一个通过分析函数调用图中敏感API调用与中心节点之间的平均亲密度来自动检测Android恶意软件的系统。
3 定义
在介绍我们提出的方法之前,我们首先描述本文中使用的正式定义。
3.1 中心性
中心性概念最初是在社交网络分析中发展起来的,它量化了节点在网络中的重要性。中心性度量对网络分析非常有用,许多研究已经提出在不同领域使用中心性度量,例如:生物网络[34]、合著网络[39]、交通网络[30]、犯罪网络[18]、附属网络[22]等。在社交网络中已经提出了几种中心性的定义,例如:
定义1. 节点的度中心性[26]是指它与其他节点相连的比例。度中心性值通过除以图中可能的最大度数(N-1,其中N是图中节点的数量)来进行归一化:
其中
定义2. Katz中心性[35]基于节点邻居的中心性来计算节点的中心性。节点i的katz中心性为:
注意,A是图G的邻接矩阵,其特征值为λ。参数β控制初始中心性,且
定义3. 接近中心性[26]表示一个节点与网络中所有其他节点的接近程度。它被计算为从该节点到图中每个其他节点的最短路径长度的平均值。节点的平均最短距离越小,该节点的接近中心性就越大。换句话说,平均最短距离和相应的接近中心性呈负相关:
注意,
定义4. 谐波中心性[42]在接近中心性的定义中反转了求和和倒数运算:
注意,
3.2 亲密度
一方面,如果两个函数之间存在更多的可达路径,那么这两个函数之间的"通信"可以被认为是频繁的。另一方面,如果两个函数之间的距离较短,那么它们之间的"通信"可以被认为是容易的。在本文中,如果两个函数之间的"通信"是频繁且容易的,那么它们将被视为一对亲密的函数。
定义5. 给定一个函数调用图
注意,n表示a和b之间可达路径的数量,
4 系统架构
在本节中,我们介绍IntDroid,一个基于函数调用图中敏感API调用和中心函数调用之间亲密度分析的自动Android恶意软件检测系统。算法1展示了我们系统的完整流程。
4.1 概述
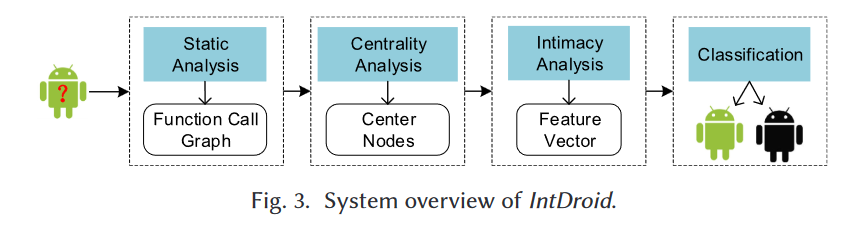
如图3所示,IntDroid包含四个主要阶段:静态分析、中心性分析、亲密度分析和分类。
-
静态分析:这个阶段旨在基于静态分析提取应用程序的函数调用图,其中每个节点是一个函数,可以是API调用或用户定义的函数。
-
中心性分析:在获得函数调用图后,我们计算调用图中所有节点的中心性。中心性排名前n%的节点将被选为中心节点。
-
亲密度分析:接下来,我们计算函数调用图中敏感API调用和中心节点之间的平均亲密度。这个阶段的输出是特征向量。
-
分类:在最后阶段,给定特征向量,我们可以使用机器学习分类器准确且高效地将应用程序分类为良性或恶意。
4.2 静态分析
在本文中,我们旨在将基于图的方法的有效性与基于社交网络分析的方法的可扩展性相结合。因此,我们通过对给定的APK文件执行低成本的程序分析(例如,上下文不敏感和流不敏感分析)来提取简洁的函数调用图。具体来说,我们基于Android逆向工程工具Androguard[19]实现静态分析。
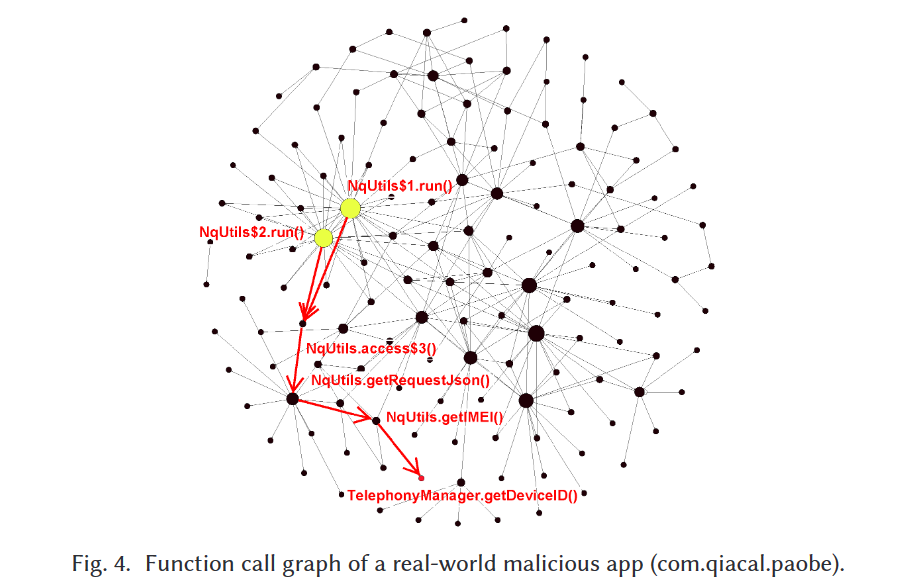
为了更好地说明我们系统中涉及的不同阶段,我们选择了一个真实世界的恶意软件样本。图4显示了该样本的函数调用图,其中每个节点是一个API调用或用户定义的函数。节点和边的数量分别为140和251。
输入:
A: 一个APK文件
t: 用于挖掘中心节点的中心性度量类型
n: 中心性排名前n%的节点将被选为中心节点
S: 敏感API调用列表
输出:
AI: 敏感API调用和中心节点之间的平均亲密度
1: CG ← extractCallGraph(A)
2: V ← obtainNodes(CG)
3: for each v ∈ V do
4: centrality ← computeCentrality(CG, v, t)
5: Centralities.add(centrality)
6: end for
7: for each v ∈ V do
8: ranking ← computeRanking(Centralities, v)
9: if ranking/len(V) ≤ n% then
10: CenterNodes.add(v)
11: end if
12: end for
13: for each s ∈ S do
14: for each c ∈ CenterNodes do
15: i ← computeIntimacy(CG, s, c)
16: I.add(i)
17: end for
18: ai ← computeAverageIntimacy(I)
19: AI.add(ai)
20: end for
21: return AI
4.3 中心性分析
如前所述,我们将函数调用图视为社交网络。因此,在这个阶段,我们的目标是挖掘调用图社交网络中最重要的"人物"。这个阶段对应算法1中的第2-12行。由于中心性度量可以表示节点在网络中的重要性,我们执行中心性分析来选择调用图中的中心节点。给定一个调用图,我们计算图中所有节点的中心性。中心性排名前n%的节点将被视为中心节点。为了进行更全面的实验,我们选取了八个不同的n值,分别是1、2、3、4、5、6、7和8。此外,对于中心性度量,我们选择度中心性、katz中心性、接近中心性和谐波中心性来开展实验。
另外,由于不同的中心性从不同角度衡量顶点的重要性,因此顶点的重要性通常需要使用多个中心性来衡量。因此,为了研究的完整性,我们通过整合四个单独的中心性度量构造了另外两个中心性。一个是通过计算前四个中心性度量的平均值得到的平均中心性,另一个是通过合并四个单独中心性度量获得的中心节点得到的全中心性。
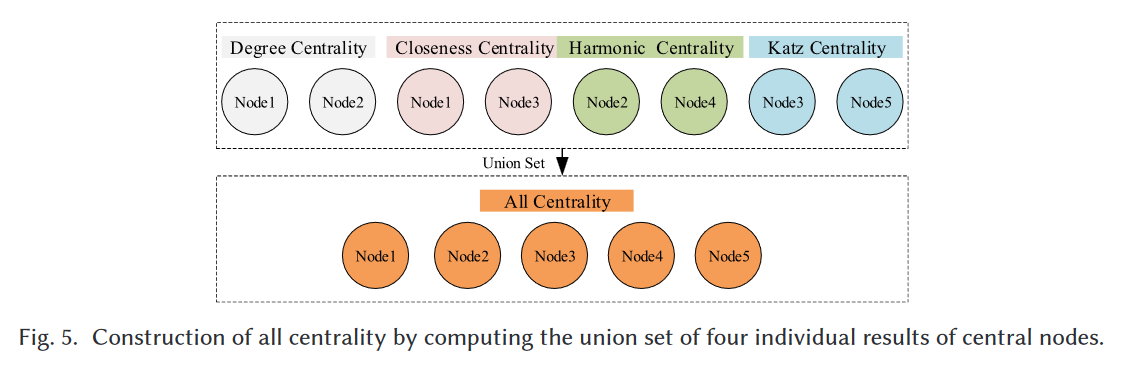
如图5所示,假设在度中心性分析后,我们在图4中选择node1和node2作为中心节点。类似地,在接近中心性、谐波中心性和katz中心性分析后,中心节点分别是(node1, node3)、(node2, node4)和(node3, node5)。然后将这四个中心节点结果的并集计算为全中心性的中心节点,即node1、node2、node3、node4和node5。
如图4所示,我们首先计算所有节点的度中心性。为了在图4中更清晰地呈现,我们使用度中心性作为节点大小的权重(即度中心性越大,节点越大)。图4中函数调用图的节点数为140,因此,我们选择度中心性排名前24的节点作为中心节点,即NqUtils$1.run()和NqUtils$2.run()。我们将这两个节点标记为黄色,以区别于图4中的其他节点。
4.4 亲密度分析
由于API调用被Android应用用于访问操作系统功能和系统资源,它们可以用作Android应用行为的表示。特别是,Android恶意软件通常调用一些与安全相关的API调用来执行恶意活动。例如,getDeviceID()可以获取手机的IMEI,getLine1Number()可以获取手机号码。因此,为了表征恶意行为,我们基于PScout[13]报告的结果关注这些与安全相关的API调用,即敏感API调用,其中包含21,986个敏感API调用。
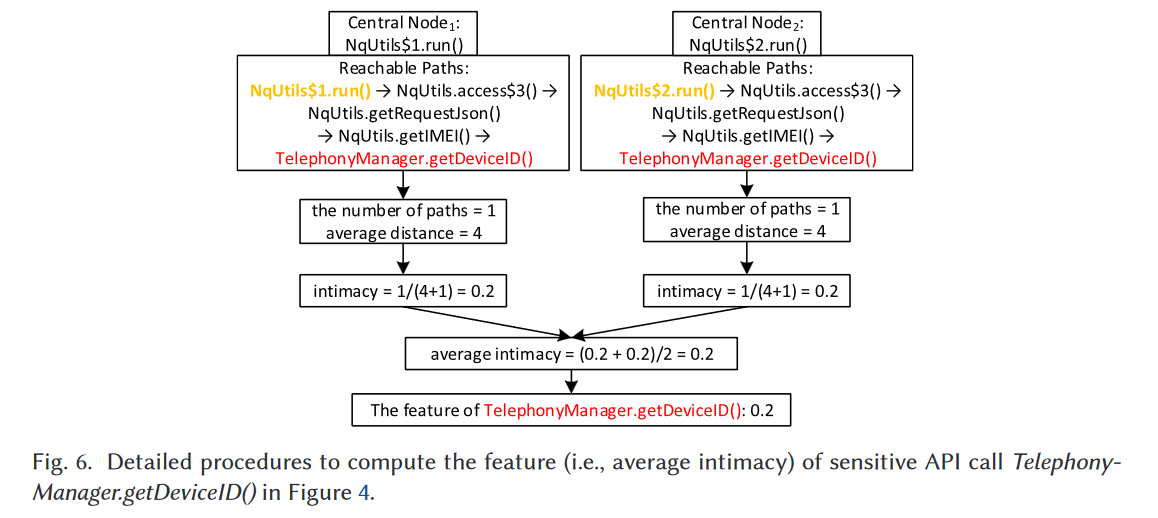
算法1中的第13-21行显示了亲密度分析。在计算敏感API调用和中心节点之间的所有亲密度后,我们使用这些亲密度的平均值作为该敏感API调用的相应特征。例如,在度中心性分析后,我们选择NqUtils$1.run()和NqUtils$2.run()作为中心节点,并在图4中将它们标记为黄色。我们选择敏感API调用TelephonyManager.getDeviceID()作为示例来说明亲密度分析的详细步骤。
如图6所示,我们首先执行可达性分析以获得TelephonyManager.getDeviceID()和中心节点(即NqUtils$1.run()和NqUtils$2.run())之间的可达路径。图4中的结果显示,TelephonyManager.getDeviceID()和NqUtils$1.run()之间有一条路径:NqUtils$1.run() → NqUtils.access$3() → NqUtils.getRequestJson() → NqUtils.getIMEI() → TelephonyManager.getDeviceID()。也就是说,可达路径的数量为1(即n=1),平均距离为4(即ad=4)。因此,TelephonyManager.getDeviceID()和NqUtils$1.run()之间的亲密度为1/(4+1)=0.2。类似地,TelephonyManager.getDeviceID()和另一个中心节点NqUtils$2.run()之间也有一条路径,它们之间的亲密度也是1/(4+1)=0.2。然后这两个亲密度的平均值可以计算为(0.2+0.2)/2=0.2,换句话说,TelephonyManager.getDeviceID()的特征是0.2。此外,在特征向量中,未出现在函数调用图中的其他敏感API调用用0表示。
4.5 分类
我们的最后阶段关注分类,即将应用标记为良性或恶意。为此,我们选择了三种不同的分类算法:1-最近邻(1-NN)、3-最近邻(3-NN)和随机森林(RF)来完成分类。从训练数据集提取的特征向量被输入到学习模型中以训练分类器,然后在测试数据集上执行分类。
5 评估
在本节中,我们旨在回答以下研究问题:
- RQ1:IntDroid在从不同方面检测Android恶意软件的有效性如何?
- RQ2:与其他最先进的Android恶意软件检测方法相比,IntDroid的有效性如何?
- RQ3:IntDroid在检测Android恶意软件时的运行时开销是多少?
- RQ4:IntDroid能否检测零日恶意软件?
表3. 我们实验中使用的数据集摘要
| 类别 | 应用数量 | 平均大小 (MB) |
|---|---|---|
| 良性应用 | 3,988 | 3.45 |
| 恶意应用 | 4,265 | 3.97 |
| 总计 | 8,253 | 3.72 |
表4. 我们实验中使用的指标描述
| 指标 | 缩写 | 定义 |
|---|---|---|
| 真阳性 | TP | 正确分类为恶意的样本数 |
| 真阴性 | TN | 正确分类为良性的样本数 |
| 假阳性 | FP | 错误分类为恶意的样本数 |
| 假阴性 | FN | 错误分类为良性的样本数 |
| 真阳性率 | TPR | TP/(TP+FN) |
| 假阴性率 | FNR | FN/(TP+FN) |
| 真阴性率 | TNR | TN/(TN+FP) |
| 假阳性率 | FPR | FP/(TN+FP) |
| 准确率 | A | (TP+TN)/(TP+TN+FP+FN) |
| 精确率 | P | TP/(TP+FP) |
| 召回率 | R | TP/(TP+FN) |
| F值 | F1 | 2PR/(P+R) |
5.1 数据集和指标
我们用于评估IntDroid的数据集包含8,253个样本,这些样本可在github上获取,研究人员可以进行可重复的实验。我们从AndroZoo[11]爬取了这些APK文件,AndroZoo目前包含超过一千万个APK文件,每个文件都已被VirusTotal[7]中的多个不同防病毒产品检测过。我们利用检测报告来过滤和生成我们的数据集。只有当所有报告都将APK文件归类为非恶意时,该文件才被视为良性。对于恶意样本,我们采用Drebin[12]中的选择方法,即当一个应用被两个以上的防病毒扫描器标记为恶意时,该应用就会被收集,这样做的目的是生成更准确的数据集。
我们的最终数据集包括3,988个良性应用和4,265个恶意应用。表3列出了我们数据集的摘要。最大的良性样本大小为45.81 MB,最小的良性样本大小为67 KB。对于恶意软件,最大样本大小为69.69 MB,最小样本大小为54 KB。为了评估IntDroid,我们通过对数据集进行10折交叉验证来进行实验,这意味着数据集被分成十个子集,每次我们选择一个子集作为测试集,其余九个子集作为训练集。我们重复这个过程十次,并将平均值作为最终结果。用于衡量IntDroid有效性的指标如表4所示。
5.2 检测有效性
我们首先评估IntDroid在检测Android恶意软件方面的有效性。为此,我们对我们的数据集进行10折交叉验证。具体来说,我们从以下三个方面评估IntDroid的有效性:
-
不同的分类模型:1NN、3NN和随机森林
-
不同的中心性度量:度中心性、接近中心性、谐波中心性、katz中心性、平均中心性和全中心性
-
选择不同前n%中心性的节点作为中心节点:1、2、3、4、5、6、7和8
5.2.1 不同的分类模型
我们首先使用第4.5节中讨论的不同机器学习算法进行一系列实验。具体来说,我们使用1-最近邻(1NN)、3-最近邻(3NN)和随机森林(RF)运行IntDroid。这三个分类器是使用Python库scikit-learn[6]实现的。对于RF,我们采用默认参数来开展实验。
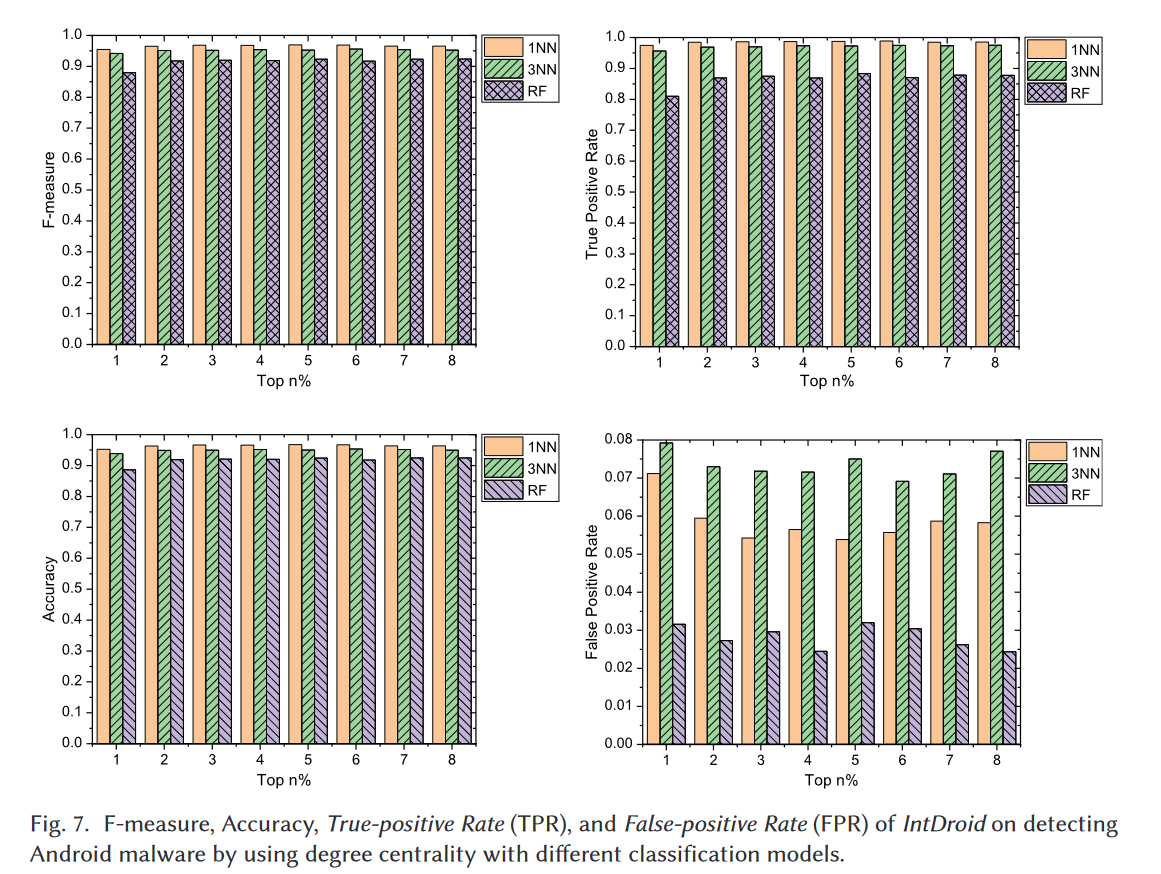
图7展示了当我们选择度中心性来挑选调用图中的中心节点时,IntDroid达到的F值、准确率、真阳性率(TPR)和假阳性率(FPR)。图7中的结果表明,1NN在所有实验中都能在F值、TPR和准确率方面保持最佳效果。例如,当我们选择度中心性排名前3%的节点作为中心节点时,使用1NN的IntDroid的F值为96.8%,而使用3NN和RF分别为95.2%和92.0%。对于TPR,当IntDroid使用1NN进行分类时,它可以获得比使用3NN和RF更好的性能。如图7所示,使用1NN的IntDroid的TPR范围在97.4%到98.9%之间,而使用RF时范围在81.0%到88.3%之间。对于FPR,当我们使用RF训练分类器时,IntDroid能够检测到更多的良性应用,但是TPR非常低,这表明更多的恶意样本被错误分类为良性应用。
事实上,对于Android恶意软件检测来说,保持高TPR非常重要,因为低TPR意味着更多的恶意样本被错误分类为良性样本,这些错误分类的恶意样本仍然可以传播恶意活动。当用户安装这些规避检测的恶意软件时,他们的私人数据可能被攻击者窃取,这可能导致不同程度的经济损失。总之,当我们采用1NN来训练分类器并用它来检测Android恶意软件时,IntDroid能够获得更好的结果。
5.2.2 不同的中心性度量
为了测试IntDroid使用不同中心性选择中心节点来检测Android恶意软件的有效性,我们首先通过采用以下四种中心性进行四个实验:度中心性、接近中心性、谐波中心性和katz中心性。此外,在社交网络中通常通过组合多个中心性度量来衡量顶点的重要性。因此,我们通过使用前四个单独中心性的平均值来挑选调用图中的中心节点,添加了一个平均中心性实验。此外,我们还通过计算前四个单独中心节点结果的并集(图5)构建了另一个实验(即全中心性)。
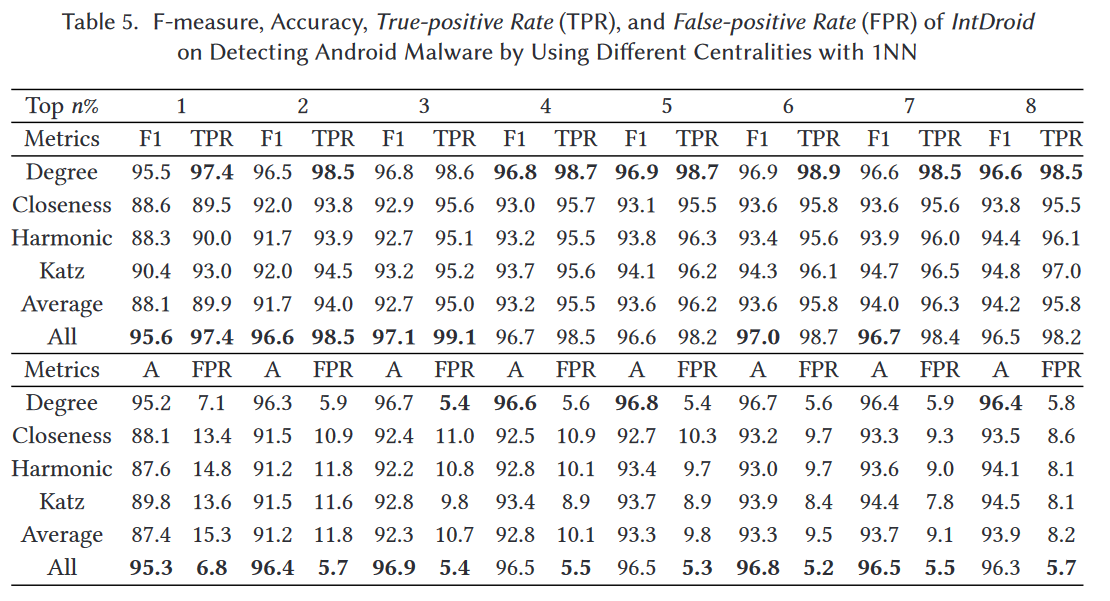
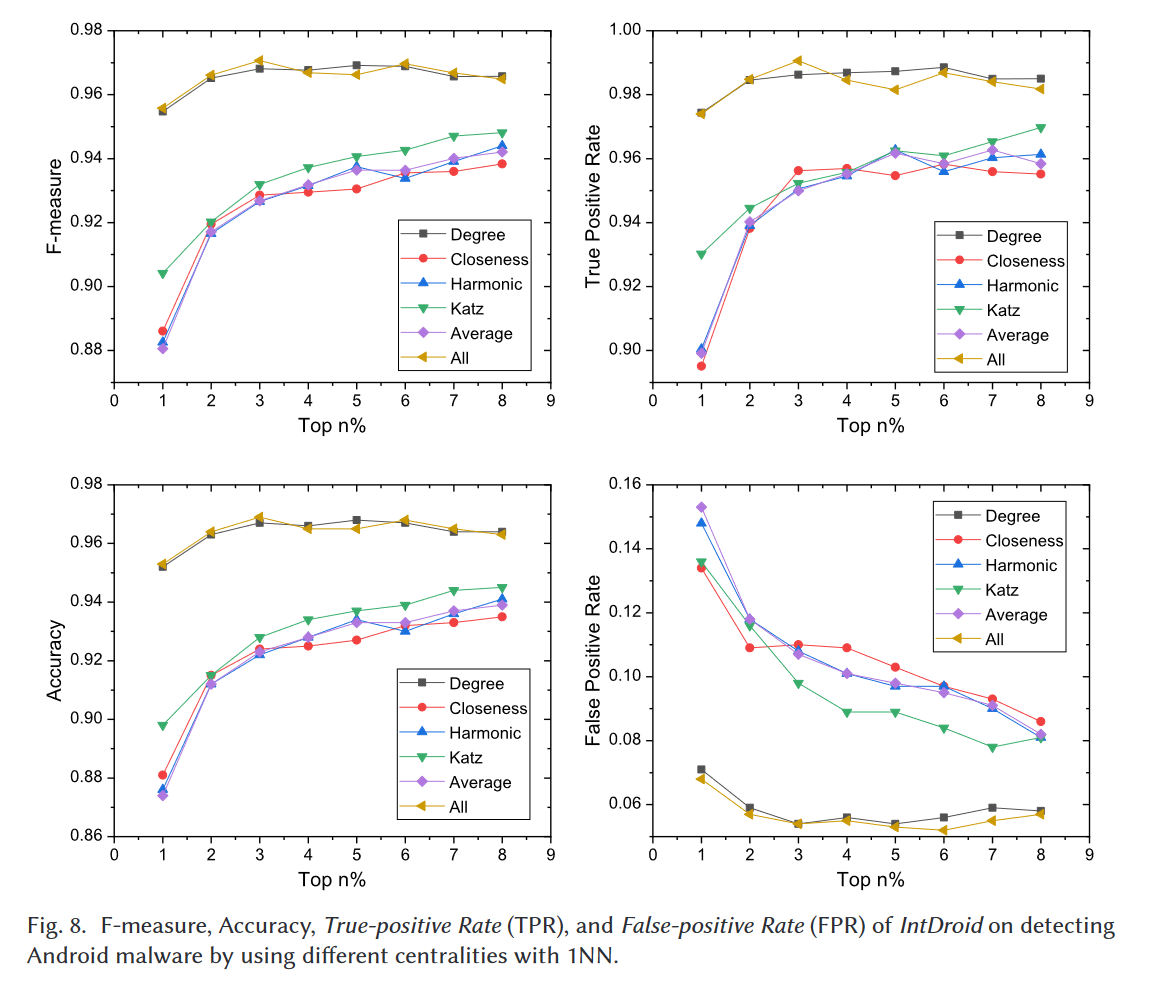
表5和图8展示了使用1NN的IntDroid的实验结果,包括每个实验的F值、准确率、TPR和FPR。表5和图8中的结果表明,当我们选择度中心性和全中心性来挖掘中心节点时,IntDroid可以获得更好的效果。例如,当中心性度量为度中心性和全中心性时,IntDroid的F值分别为96.8%和97.1%,而当我们选择接近中心性、谐波中心性、katz中心性和平均中心性来挑选调用图中的中心节点时,F值分别为92.9%、92.7%、93.2%和92.7%。对于TPR,如表5和图8所示,当我们采用全中心性来提取中心节点时,IntDroid能够保持99.1%的TPR。总之,当我们采用度中心性和全中心性来挖掘调用图中的中心节点时,IntDroid可以获得更好的效果。
5.2.3 不同的前n%
n越大,中心节点越多,导致运行时开销越大(第5.4节)。因此,我们只选择八个不同的n值,并排除较大的数字。如图8所示,F值、准确率、TPR和FPR随n值的变化而变化。对于度中心性和全中心性,随着n的增加,检测结果变化缓慢。对于其他选定的中心性度量,F值、准确率和TPR通常与n值呈正相关,FPR通常与n呈负相关。此外,无论n是多少,当我们选择度中心性或全中心性来提取调用图中的中心节点时,IntDroid总能保持更好的效果。
5.3 与先前工作的比较
在本节中,我们将IntDroid与VirusTotal[7]中的30个防病毒扫描器和三种最先进的Android恶意软件检测方法进行比较:一种基于权限的方法(即PerDroid[53])、一种传统的基于图的方法(即MaMaDroid[43])和一种基于社交网络分析的系统(即MalScan[54])。为了在图中更清晰地显示,我们仅展示表5中所有48个实验结果中IntDroid的最佳结果。
5.3.1 与防病毒扫描器的比较
如前所述,我们的数据集来自AndroZoo[11],每个APK文件都已被VirusTotal[7]中的不同防病毒产品检测过。我们利用检测报告来生成数据集。只有当所有报告都将APK文件归类为非恶意时,该文件才被视为良性。换句话说,我们数据集中的良性应用都在防病毒扫描器可以检测的范围内。因此,在本小节中,我们关注数据集中4,265个恶意软件样本的检测率。
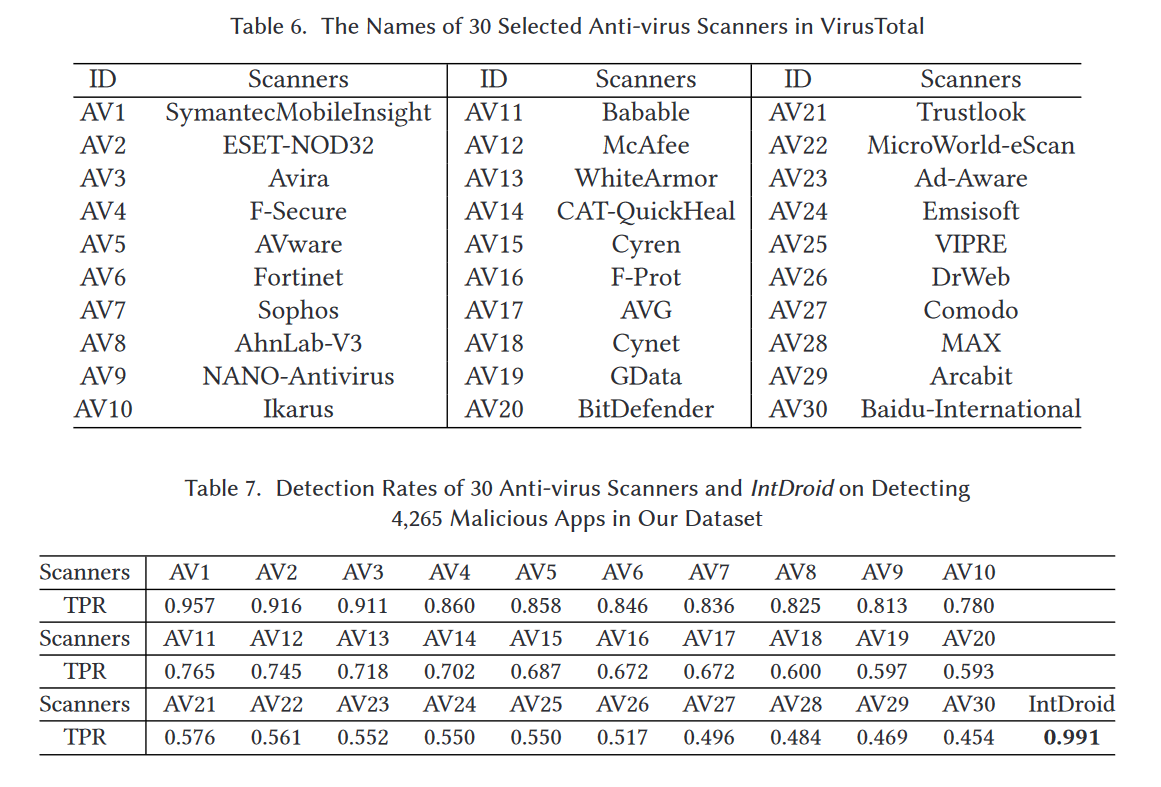
具体来说,我们将这4,265个恶意软件样本上传到VirusTotal以生成检测报告。在获得所有报告后,我们在表7中显示了所有防病毒扫描器的前30个TPR,这30个扫描器的名称在表6中列出。从表7的结果中,我们可以看到这些防病毒扫描器的TPR差异很大。例如,SymantecMobileInsight可以检测到我们数据集中超过95%的恶意软件,而Baidu-International只能检测到4,265个恶意样本中的45%。对于IntDroid,TPR令人鼓舞,因为它可以发现我们数据集中超过99%的恶意软件,这是VirusTotal中所有扫描器中最高的。
此外,我们还研究了IntDroid和这30个防病毒扫描器检测到的恶意软件的重叠情况。我们发现,虽然IntDroid可以检测到比这30个防病毒扫描器更多的恶意软件,但IntDroid的七个假阴性(即被IntDroid错误分类的恶意软件)被某些扫描器正确检测到。我们随后手动分析了这些恶意软件,结果显示它们都是灰色软件。灰色软件是一种不必要的应用,它不一定是恶意的,但如果不处理,可能会导致性能问题和安全风险。换句话说,IntDroid可以检测到被30个扫描器错误分类的恶意软件,这30个扫描器也可以检测到被IntDroid错误分类的恶意软件。因此,我们可以将IntDroid与VirusTotal中的其他防病毒扫描器结合,以实现更完整的恶意软件检测。
5.3.2 与PerDroid的比较
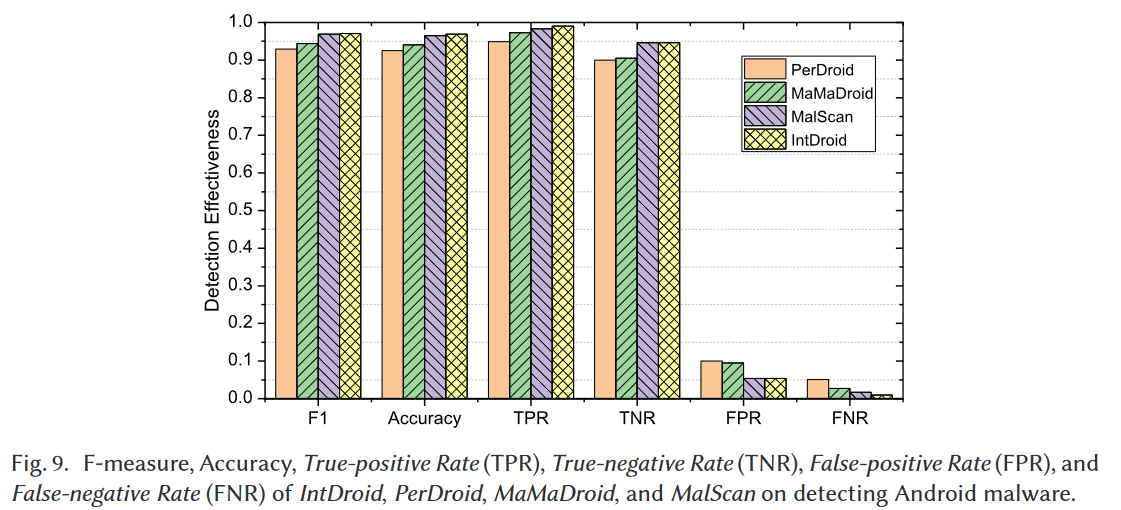
Wang等人[53]提出了一种基于风险权限的Android恶意软件检测方法,这些风险权限是提供对移动系统核心设施访问控制机制的安全感知特征。他们应用三种特征排名方法(即互信息、相关系数和T检验)来对Android个别权限进行风险排名。然后将排名靠前的风险权限用作恶意软件检测的特征。我们利用他们论文中报告的权限风险排名,并使用他们公共网站[1]中列出的前88个风险权限。具体来说,我们使用Androguard[19]构建特征,并将其输入到三个机器学习分类器中,即1NN、3NN和RF。通过对我们8,253个样本的实验结果,我们发现3NN能够在这三个分类器中保持最佳效果。图9展示了IntDroid和PerDroid[53]的比较结果,这些结果表明我们提出的方法比基于权限的方法更有效。例如,F值和准确率分别为92.9%和92.5%,而IntDroid可以分别达到97.1%和96.9%。这种观察主要是由于基于权限的方法缺乏程序语义。
5.3.3 与MaMaDroid的比较
我们还将IntDroid与一种最先进的基于图的方法MaMaDroid[43]进行比较,该方法利用从调用图获得的抽象函数调用序列,并使用它来提取特征进行分类。这些抽象序列用于构建马尔可夫链模型来表示函数之间的传输概率。具体来说,我们使用他们网站[2]上的MaMaDroid开源代码进行抽象、建模和特征提取。为了完成分类,我们实现了他们论文中描述的三个分类器(即1NN、3NN和RF),这些分类器在他们的源代码中没有提供。
图9给出了IntDroid和MaMaDroid在F值、准确率、TPR、TNR、FPR和FNR方面的比较结果。从图9的结果中,我们可以看到MaMaDroid优于基于权限的方法,这是因为MaMaDroid保留了程序语义(即它将程序语义提炼为图形表示),而基于权限的方法忽略了它们。此外,比较结果还表明IntDroid能够检测到更多的恶意软件,并获得比MaMaDroid更好的效果。使用IntDroid时,F值和TPR能够保持在97.1%和99.1%,而使用MaMaDroid时为94.4%和97.3%。这主要是因为API调用的抽象可能会导致一些误报。例如,两个完全不同的API调用TelephonyManager.getDeviceId()和SmsManager.sendTextMessage()可以被抽象到同一个包android.telephony中。
5.3.4 与MalScan的比较
为了实现市场范围的移动恶意软件扫描,MalScan[54]将应用程序的函数调用图视为复杂的社交网络,并对敏感API调用应用中心性分析来提取图的语义特征。然后这些中心性值用于训练Android恶意软件检测的模型。如MalScan[54]所述,我们可以看到,当使用连接中心性来训练1NN模型进行恶意软件检测时,MalScan的平均检测效果能够保持最佳。因此,我们提取调用图中敏感API调用的连接中心性来训练1NN模型以完成比较实验。
从图9中呈现的结果可以看出,由于考虑了应用程序的图语义,MalScan可以获得比基于权限的方法更好的效果。此外,IntDroid能够保持比MalScan略好的效果。例如,使用MalScan时TPR为98.3%,而使用IntDroid进行分类时为99.1%。这是因为仅使用敏感API调用的中心性来进行恶意软件检测可能会在良性应用通过调用敏感API表现出与恶意软件类似的行为时导致一些误报和漏报。例如,一些社交应用(如抖音)需要访问用户的位置来呈现特定位置的新闻或视频,并读取用户的通讯录来推荐新朋友。在这种情况下,敏感API调用LocationManager.getLastLocation()的中心性可能与某些恶意软件几乎相同。
然而,当我们使用敏感API调用和中心节点之间的亲密度来检测恶意软件时,这些良性应用和恶意软件的中心节点是不同的,导致不同应用中相同敏感API调用与中心节点之间的亲密度不同。换句话说,虽然敏感API调用的中心性值相似,但API调用和中心节点之间的亲密度可能不同,因为良性应用和恶意软件中的中心节点是不同的。通过这种方式,我们可以在较低的漏报率下检测到更多的恶意软件。
5.4 运行时开销
在本节中,我们使用8,253个样本(即3,988个良性样本和4,265个恶意样本)对IntDroid的运行时开销进行全面评估。这8,253个样本的平均节点数和边数分别为4,779和10,159。对于一个新的应用,IntDroid包含四个主要步骤来完成分类:(1)函数调用图提取,(2)中心性分析,(3)亲密度分析,和(4)分类。
5.4.1 函数调用图提取
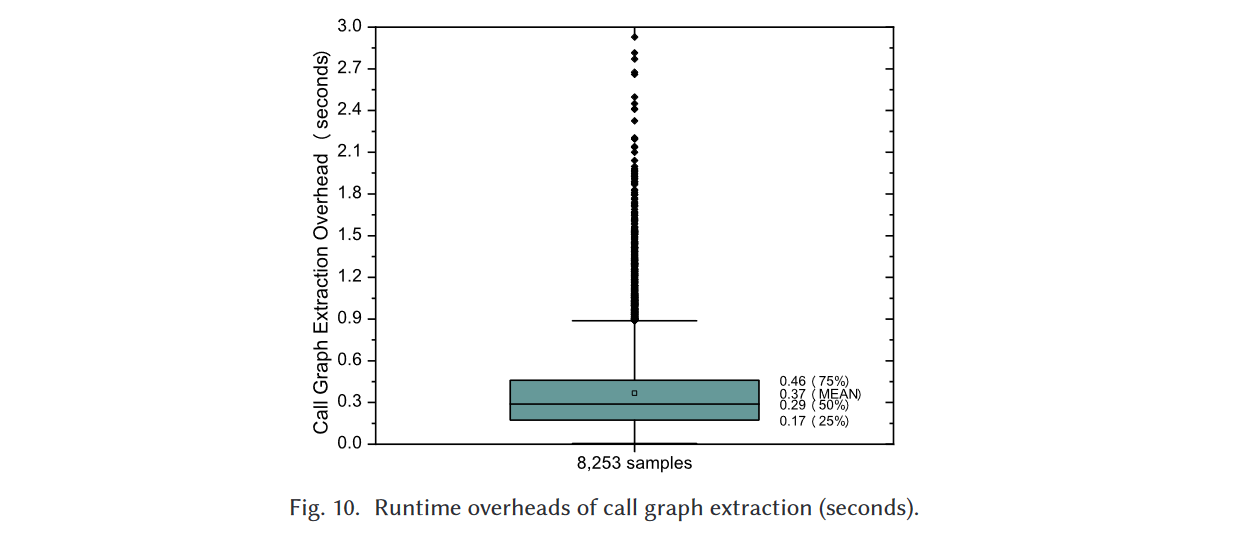
IntDroid的第一步是为给定的APK文件提取函数调用图。图10展示了我们数据集上调用图提取的运行时开销,对于超过99%的APK文件,我们可以在2秒内获得调用图。平均而言,为给定的APK文件构建调用图需要0.37秒。
5.4.2 中心性分析
IntDroid的第二步是进行中心性分析以发掘函数调用图中的中心节点。如表8和图11所示,平均运行时开销根据不同的中心性度量而变化。显然,平均中心性和全中心性的运行时间大约是四个单独中心性的总和,这是合理的,因为这两个中心性是度中心性、接近中心性、谐波中心性和Katz中心性的组合。
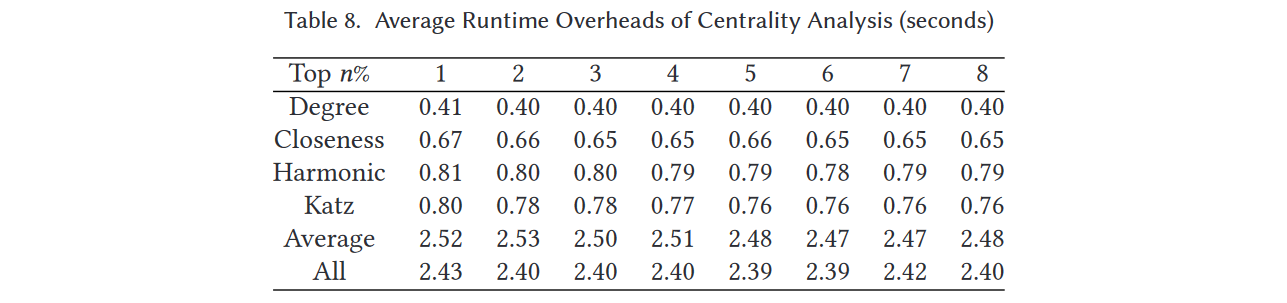
5.4.3 亲密度分析
IntDroid的第三步是执行亲密度分析以提取特征向量。表9和图11展示了IntDroid在这一步骤的平均运行时开销,这些结果表明亲密度分析的平均运行时间通常与前n%呈正相关。这种观察主要是因为n越大,中心节点越多,导致提取敏感API调用和中心节点之间的平均亲密度需要更多的运行时开销。
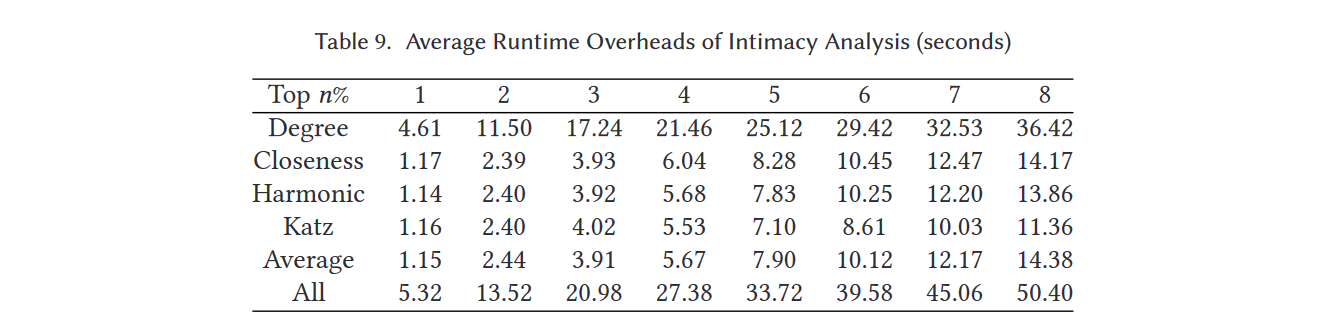
5.4.4 分类
IntDroid的最后一步是使用从亲密度分析步骤获得的特征向量训练分类器,并在测试数据集上执行分类。如表10和图11所示,完成分类消耗不到0.02秒。分类的运行时开销是四个步骤中最少的。
表11和图11展示了IntDroid分析给定APK文件的总平均运行时开销。当我们选择度中心性排名前1%的节点作为中心节点并进行亲密度分析以生成用于分类的特征向量时,总运行时开销平均仅为5.4秒,而TPR能够保持在97.4%。
一方面,PerDroid[53]是一种基于权限的方法,其在恶意软件检测方面的效果低于MaMaDroid[43]和MalScan[54]。另一方面,IntDroid是传统基于图分析方法与基于社交网络分析方法的结合。因此,我们主要关注IntDroid与传统基于图分析方法(即MaMaDroid)和基于社交网络分析方法(即MalScan)的运行时开销比较。
对于MaMaDroid,表12显示平均需要约33.83秒来完成一次分类。虽然MaMaDroid的运行时开销可以与IntDroid几乎相同,但它需要比IntDroid多7倍的内存来执行分类。MaMaDroid需要63.7 GB的内存来完成对我们8,253个样本的分类,而IntDroid只需要8.5 GB。这是因为MaMaDroid的特征向量维度为115,600,而我们提出的方法为21,986。
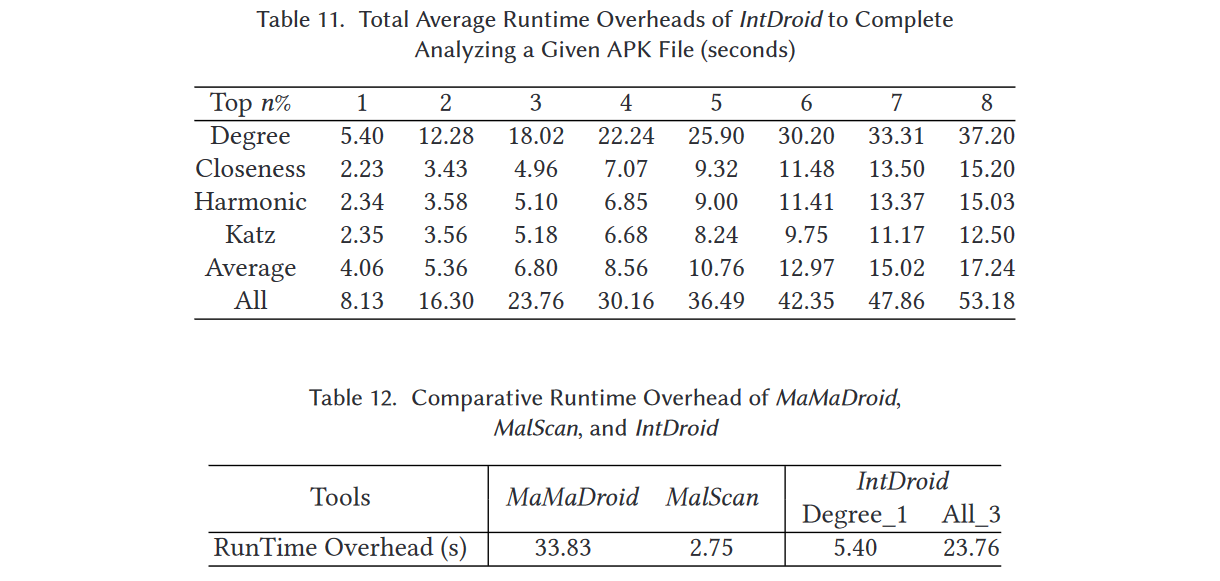
此外,由于IntDroid的亲密度分析,其检测效率低于MalScan。例如,当我们将度中心性排名前1%的节点作为中心节点,使用1NN算法训练分类器时,IntDroid需要约5.4秒来分析给定的应用,而当我们提取连接中心性作为特征来训练1NN分类器时,MalScan只需要2.7秒就能完成整个分析。然而,由于IntDroid的更高效性,IntDroid和MalScan可以互补。换句话说,MalScan可以作为第一道防线来过滤大多数恶意软件,然后IntDroid可以作为第二道防线来挖掘更多恶意软件。通过这种方式,我们可以节省更多的时间和资源。
例如,假设给定10,000个新应用,我们可以先使用MalScan来检测这些应用。然后将MalScan分类为良性的应用输入到IntDroid中进行深入分析,以发现更多的恶意应用。通过这种方式,与仅使用IntDroid分析这10,000个应用相比,我们可以节省更多时间。在实践中,IntDroid和MalScan都无法达到100%的检测准确率。因此,在收集所有检测到的恶意软件样本后,我们可以将它们上传到VirusTotal以生成更详细的报告,帮助分析人员从这些恶意软件中过滤出良性应用。
5.5 零日恶意软件的检测
在本小节中,我们想要检查IntDroid在发现真实世界恶意软件方面的能力。为了实现这个目标,我们将全中心性排名前3%的节点作为中心节点,并利用我们的8,253个样本使用1NN算法训练分类器。接下来,我们从GooglePlay市场爬取5,000个应用并将它们输入到训练好的1NN分类器中。在这些应用中,IntDroid报告其中32个为恶意软件。为了验证这32个应用是否确实是恶意软件,我们将它们上传到VirusTotal[7]进行分析。在这32个样本中,24个被至少两个防病毒扫描器报告为恶意软件。
为了进一步研究这24个样本的行为,我们将它们上传到一个最先进的沙箱[8],该沙箱结合静态和动态分析来报告详细的风险行为。通过结果,我们观察到它们都收集用户的私人信息(如IMSI、IMEI、电话号码和联系人),然后将它们发送到网络或写入文件。此外,其中七个执行shellcode来完成更多风险活动。分析这些样本后,我们对它们进行调查(即从GooglePlay官方网站获取更详细的信息),结果显示其中一个已被超过一千万用户下载和安装。这个应用也被VirusTotal[7]中的六个防病毒扫描器标记为恶意软件,其中之一是Symantec Mobile Insight。
实际上,三个应用在VirusTotal中只被一个扫描器标记为恶意软件。同样,我们也将它们上传到沙箱[8],行为报告显示它们不一定是恶意的,而是被识别为一种灰色软件(即广告软件)。对于剩下的五个应用,我们手动检查了它们。我们的手动检查显示,这五个应用中的一个实际上是恶意软件,因为它包含高度可疑的行为。该应用是一个音乐下载器,包含六个危险权限,并读取设备的电池和内存信息。此外,该应用收集许多敏感数据(即Android ID、序列号、IMSI、IMEI、电话号码、联系人、电子邮件和位置),甚至可以执行shellcode。
总之,IntDroid能够在5,000个GooglePlay应用中发现28个零日恶意软件,其中一个已被超过1000万用户下载和安装,另一个未被现有工具[7]报告为恶意软件。
6 与MALSCAN的广泛比较
因为IntDroid最相似的系统是MalScan,因此,为了验证IntDroid的更高效性,我们在本节中与MalScan进行广泛比较。从第5节中的实验结果来看,当我们选择全中心性排名前3%的节点作为中心节点并应用1NN来训练恶意软件检测模型时,我们能够保持最佳效果。我们选择这三个参数来开始与MalScan的比较。
6.1 暮光区恶意软件的检测
如前所述,灰色软件样本是一种不必要的应用,它不一定是恶意的,但如果不处理,可能会导致性能问题和安全风险。根据最近的一份报告,即使灰色软件不是主动恶意的,它们也可能造成大量损害。由于灰色软件的恶意行为不明显,它们更难与良性应用区分开来。在Euphony[38]中,作者发现被VirusTotal中至少五个防病毒扫描器标记的应用表现出更明显的恶意行为。换句话说,被一到五个扫描器检测到的应用很可能处于恶意和良性功能之间的暮光区。
在这部分中,我们关注使用MalScan和IntDroid检测暮光区的恶意软件(如灰色软件)。具体来说,我们随机下载3,000个被VirusTotal中一到五个扫描器报告为恶意的恶意软件样本。对于良性应用,我们使用第5节中的3,988个良性样本作为数据集。收集3,988个良性应用和3,000个恶意样本后,我们开始检查MalScan和IntDroid在检测暮光区恶意软件方面的能力。
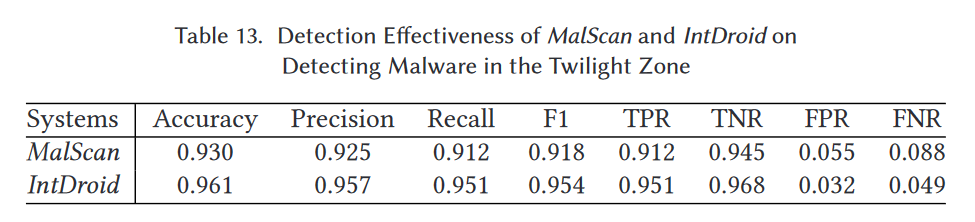
表13展示了MalScan和IntDroid的比较结果。MalScan的TPR为91.2%,这意味着MalScan只能检测到91.2%的暮光区恶意软件。然而,对于IntDroid,TPR能够保持在95.1%,这大于91.2%。这样的结果表明IntDroid在检测暮光区恶意软件方面表现优于MalScan。虽然IntDroid在检测我们收集的数据集时可以达到96.1%的准确率,但它仍然无法检测某些暮光区的恶意软件。我们随后手动检查这些错误分类的恶意软件,发现它们大多是广告软件。广告软件最常见的原因是为了赚取广告收入而收集用户信息。在实践中,一些良性应用可能使用广告库来访问用户的私人信息,甚至监控用户的行为以推送合适的广告来获取利润。这些广告库和广告软件的行为类似,导致错误分类。
6.2 不同家族恶意软件的检测
在测试恶意软件检测方法的检测效果时,还有另一个重要方面(即实验数据集中恶意软件家族的平衡[12, 48])需要考虑。假设几个恶意软件家族的样本数量远大于其他家族,那么训练模型的检测能力将主要依赖于这些家族。换句话说,恶意软件检测方法应该对不同家族都保持高效性。
在本小节中,我们进行比较实验来评估MalScan和IntDroid在检测不同家族恶意软件方面的效果。具体来说,我们选择AndroZoo[11]中20个最大的恶意软件家族作为测试对象。AndroZoo[11]中的一些恶意APK文件使用[33]中的方法被标记到相应的家族中。我们为每个家族随机下载1,000个样本,下载的样本总数为20,000个。每个家族的名称和样本平均大小可以在表14中找到。
我们利用第5节中使用的3,988个良性样本和这20,000个恶意软件样本来开展研究。实际上,我们为20个家族总共进行了20次实验。换句话说,每个实验的数据集包括3,988个良性应用和每个家族的1,000个恶意应用。我们为20个家族重复这个过程20次。所有研究都使用10折交叉验证进行。
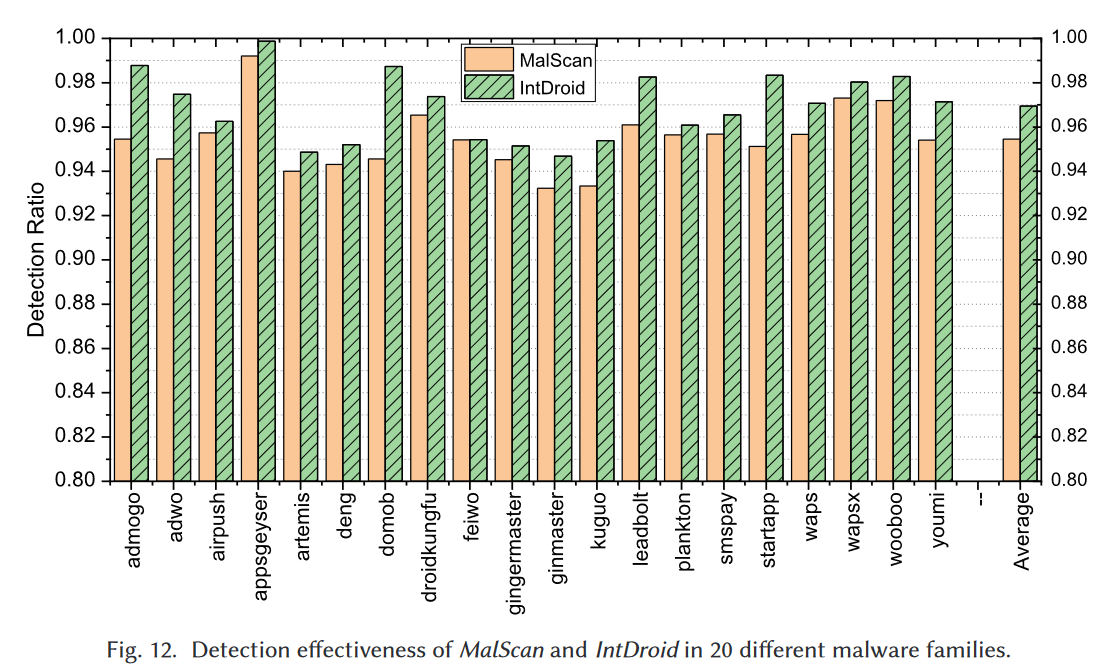
图12展示了MalScan和IntDroid对每个家族的检测效果。从图12的结果中,我们可以看到IntDroid能够在检测所有这20个家族的恶意软件时保持比MalScan更好的效果。例如,在检测admogo家族的恶意软件时,MalScan只能检测到95.5%的恶意软件,而IntDroid可以达到98.8%的TPR。此外,IntDroid能够对所有20个恶意软件家族保持超过94%的检测率。特别是,有七个家族的TPR超过98%,一个家族的TPR大于99%。在测试这23,988个样本时,IntDroid的平均检测率为96.9%,如此高的效果表明IntDroid适合检测不同家族的恶意软件。
6.3 未知家族恶意软件的检测
随着Android的不断发展,攻击者创建了许多新的恶意样本来逃避现有的恶意软件检测器[52]。这些样本中的一些可能不属于任何现有的恶意软件家族。当应用来自新的恶意软件家族时,由于缺乏区分性特征来将其标记为恶意软件,恶意软件检测器可能会产生假阴性。因此,评估恶意软件检测方法在区分新恶意软件家族方面的能力很重要。
在本小节中,我们进行比较实验来检查MalScan和IntDroid在检测未知家族恶意软件方面的效果。本小节中的数据集包括第5节中的3,988个良性样本和第6.2节中的20,000个恶意样本。我们总共进行三个实验,其中我们限制特定家族的训练样本数量。
在第一个实验中,我们在训练集中不提供该家族的任何样本。假设admogo家族是一个新家族,那么训练集将由3,988个良性样本和19,000个恶意样本组成,包括0个admogo家族样本。为了模拟新家族的开始传播,我们开始第二个实验,我们首先随机选择该家族的10个样本,然后将这些选定的样本放入训练集。这个实验中恶意训练样本的数量是19,010个,其中包括10个新家族样本。随着新家族恶意软件的扩散,可用样本的数量会增加。在最后一个实验中,我们假设获得的新家族样本数量为100,并将这100个样本放入我们的训练集。
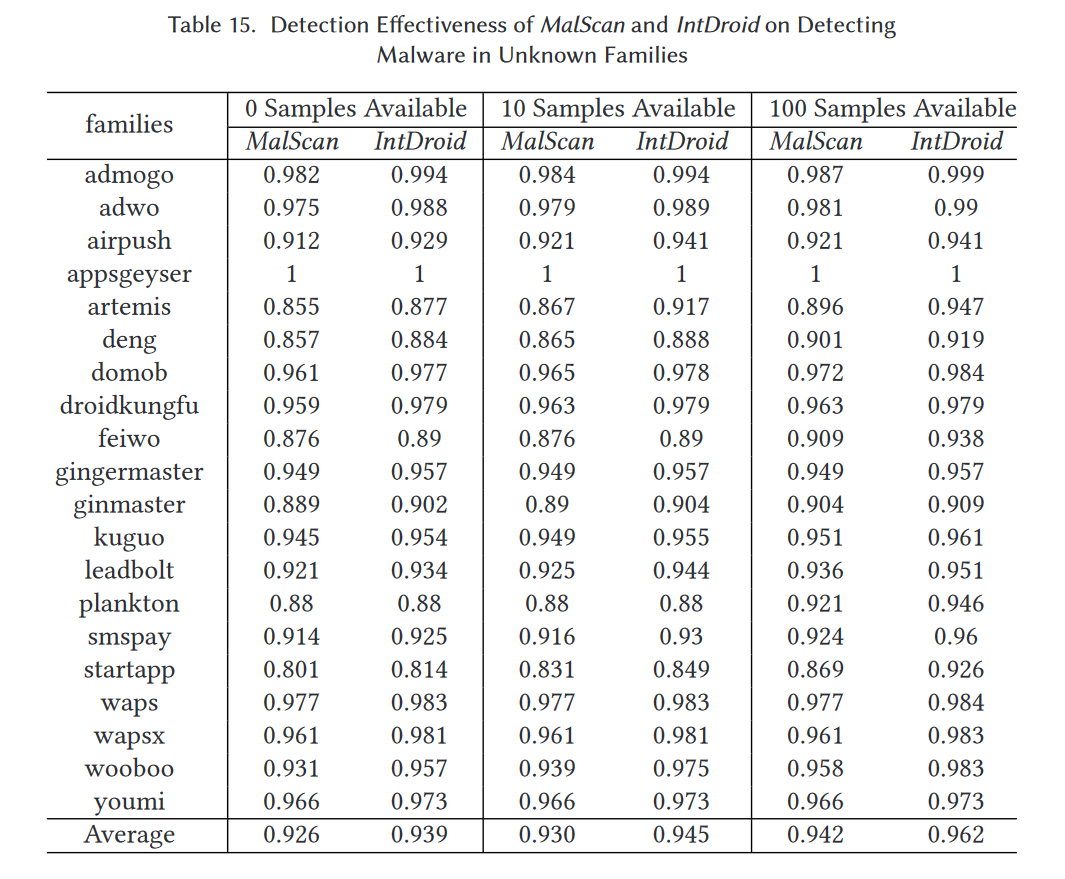
我们对每个家族进行这三个实验,检测结果在表15中呈现。如表15所示,与图12中的结果类似,IntDroid在检测所有新家族的恶意软件方面表现优于MalScan。当新家族的可用样本数量为0、10和100时,MalScan的平均TPR分别为92.6%、93.0%和94.2%。然而,它们都小于IntDroid达到的TPR。此外,在没有任何新家族样本用于训练的情况下,IntDroid的TPR仍然能够对20个不同家族保持在80%以上。此外,11个家族可以达到超过95%的TPR,甚至一个家族(即appsgeyser)可以被完美检测(即100%准确率)。这些结果表明IntDroid能够以良好的效果检测来自新家族的恶意软件。
当新家族的可用样本数量增加时,IntDroid的TPR可以达到更好的效果。例如,如果没有startapp样本可用于训练,IntDroid在检测startapp家族恶意软件时的TPR为81.4%,而当可用训练样本增加到10和100时,分别为84.9%和92.6%。这样的结果是合理的,因为某些家族的成员通常表现出类似的行为,只是带有一些轻微修改的重打包恶意软件。可用样本数量越多,可以检测到的家族变体就越多。
7 讨论和局限性
7.1 有效性威胁
外部有效性威胁:在第5节中使用有限数量的应用构成了外部有效性威胁。这些有限的应用可能无法代表整个市场。我们在第6节中使用来自20个家族的20,000个恶意应用进行其他详细的比较实验来缓解这个威胁。
内部有效性威胁:
-
当我们得出良性应用和恶意应用之间差异程度的结论时,亲密度值的分布可能会导致一些不准确。我们通过采用非参数检验(即Mann-Whitney)来研究这些亲密度值的差异来缓解这个威胁。
-
由于不同的机器运行状态(如不同的CPU使用率),记录运行时开销的不准确性是不可避免的。通过收集所有运行时开销三次后报告平均运行时开销来缓解这个威胁。
-
根据简单排序的节点中心性百分比选择中心节点可能会导致一些不准确。为了缓解这个威胁,我们选择八个阈值(即1%到8%)进行更完整的实验,以找出恶意软件检测的理想阈值。
-
在从Google Play市场检测零日恶意软件时可能会有一些误报。我们将这些样本上传到结合静态和动态分析的沙箱中,生成详细的风险报告来缓解这个威胁。
7.2 误报和漏报
误报:深入分析IntDroid造成的误报后,我们发现最常见的原因是良性应用中使用广告库。这些广告库需要访问私人信息,甚至监控用户的行为以推送合适的广告来获取利润。这些广告库的行为可能被错误分类为恶意软件,导致误报。
漏报:对于IntDroid的漏报,我们观察到它们大多数都在暮光区,即灰色软件。换句话说,这些样本的恶意代码没有表现出明显的恶意行为或被深度伪装。广告软件是一种灰色软件,是设计用来在屏幕上显示广告的不需要的软件。由于它们大多数没有执行任何明显的恶意活动,IntDroid无法正确地将它们标记为恶意软件。
7.3 讨论
在我们的工作中,我们总共选择了四个单独的中心性度量,并构造了另外两个中心性度量来挖掘Android恶意软件检测的中心节点。通过第5节的实验结果,我们看到度中心性在四个单独的中心性度量(即度中心性、katz中心性、接近中心性和谐波中心性)中可以达到最佳性能。此外,当我们使用组合的中心节点(即全中心性)来检测恶意软件时,性能与使用度中心性几乎相同。
我们进行了一个简单的研究,以检查使用度中心性和全中心性获得的特征向量之间的余弦距离。我们选择n=1(即中心性排名前1%的节点将被选为中心节点)作为参数。对于度中心性和全中心性之间3,988个良性样本的特征向量,3,921个样本(3,921/3,988=98.32%)的相似度大于90%,3,185个样本(3185/3988=79.86%)的相似度大于99%,548个样本的相似度为100%。此外,对于我们的4,265个恶意样本,4,249个样本(4,249/4,265=99.62%)的相似度大于90%,3,818个样本(3,818/4,265=89.52%)的相似度大于99%,394个样本的相似度为100%。这些结果表明度中心性可能是提取恶意软件检测中心节点的最佳候选。
在我们的未来工作中,我们将测试更多不同中心性度量在检测Android恶意软件方面的能力。此外,由于大多数Android恶意软件检测系统是闭源的,我们只将IntDroid与三个开源系统[43, 53, 54]进行比较。我们将在未来的工作中对更多系统进行详细的比较分析。
7.4 局限性
与任何经验方法一样,IntDroid存在几个局限性,列举如下:
-
敏感API调用:我们的方法依赖于调用图中敏感API调用和中心节点之间的亲密度分析。我们使用PScout[13]映射的最新版本敏感API调用。然而,它可能部分过时。一些不正确和缺失的API调用可能会导致恶意软件检测的一些误报和漏报。需要使用PScout[13]在最新的Android版本上更新敏感API调用。
-
加密:使用混淆技术保护Android应用非常普遍。考虑到IntDroid分析函数调用图来提取特征,它对几种典型的本地混淆技术[32]具有弹性,如用户定义的函数和包的重命名。然而,它容易受到某些混淆技术的影响,如加密(例如APK Protect[5])。这些加密打包器可以使用加密技术隐藏实际的Dex代码来保护应用。为了解决这个限制,我们可以使用一些解包系统[55, 59]来恢复实际的Dex文件,然后应用静态分析来提取调用图。
-
调用图提取:为了保持IntDroid在恶意软件检测方面的高效性,我们使用Androguard[19]进行简单的静态分析来提取简洁的函数调用图。实际上,许多应用使用反射技术[47]来调用敏感方法,在这种情况下,我们可能会遗漏这些方法之间的调用关系。为了对反射具有弹性,我们可以使用开源工具DroidRA[37]对我们的数据集进行反射分析,以识别每个应用中使用反射的方法。然后可以将缺失的边添加到调用图中,其中调用者节点是使用反射的方法,被调用者节点是反射的方法。此外,Androguard[19]提取的函数调用图是上下文和流不敏感的调用图。我们忽略这些信息以实现高效的恶意软件检测。如果我们执行昂贵的程序分析来考虑调用图的上下文和流信息,保持高可扩展性对我们来说是一个两难的问题。然而,我们的实验结果表明,简洁的调用图足以让我们进行有效的恶意软件检测。
8 相关工作
已经提出了许多Android恶意软件检测方法,可以分为两个主要类别:基于语法和基于语义。
8.1 基于语法的Android恶意软件检测
基于语法的方法[9, 12, 21, 31, 36, 46, 50, 53, 60]忽略应用代码的语义以实现高效的Android恶意软件检测。例如,Wang等人[53]关注应用请求的权限来检测Android恶意软件。它扫描清单文件以收集所有权限的列表,然后应用几种特征排名方法来对它们进行风险排名。在获得所有分析权限的排名后,排名靠前的权限将被视为风险权限,并用作检测恶意软件的特征。这些风险权限可以提供对移动系统核心设施的访问控制机制,因此它们可以表示为一种应用行为类型。
与Wang等人[53]类似,Huang等人[31]也从APK文件中提取权限和几个易于检索的特征(例如,扩展名为".so"的文件数量)来检测恶意软件。在实践中,由于精度有限,他们得出结论,他们的方法可以用作快速过滤器来识别恶意软件,然后应该应用更高级的技术来实现更准确的恶意软件检测。换句话说,由于缺乏程序语义,基于权限的方法在检测Android恶意软件方面效果不佳。
为了缓解这个问题,Drebin[12]使用广泛的静态分析从清单和反汇编代码中提取尽可能多的特征,并将它们嵌入联合向量空间以检测恶意软件。清单中的特征集包括硬件特征、请求的权限、应用组件和过滤的意图,而应用反汇编代码中包括受限的API调用、使用的权限、可疑的API调用和网络地址。然而,它只搜索特定字符串的存在,而不考虑程序语义。因此它可以很容易地被语法特征的攻击[17]规避。
8.2 基于语义的Android恶意软件检测
为了保持在检测Android恶意软件方面的高效性,研究人员[10, 14, 20, 23-25, 27, 28, 40, 43-44, 45, 49, 56-58]进行程序分析以提取不同类型的应用语义。例如,MassVet[16]构建一个视图图来描述具有相当复杂UI结构的应用。为了确保图匹配的高可扩展性,MassVet应用他们之前工作[15]中出现的相似性比较算法来分析恢复的视图图。它已经验证了在移动恶意软件检测方面的高效性和可扩展性,然而,MassVet的原始目的是检测重打包的恶意软件。当应用是新的恶意软件时,它可能会导致漏报。
DroidSIFT[58]基于静态分析提取加权上下文API依赖图来解决恶意软件变形问题。Apposcopy[24]利用静态污点分析形成一种称为组件间调用图的新程序表示,并使用它来检测恶意软件。然而,DroidSIFT[58]和Apposcopy[24]都存在严重的运行时开销。根据他们的论文报告,它们分别平均需要175.8秒和275秒来分析一个应用。
SMART[44]基于确定性符号自动机构建Android恶意软件的语义模型,可以捕获恶意软件家族的常见恶意行为。它包含两个主要阶段来完成恶意软件检测。第一阶段是离线模型学习,克隆检测平均消耗72.5秒,克隆差异和DSA生成消耗167.5秒。第二阶段是在线恶意软件检测和分类,其中基于ML的恶意软件检测平均需要13.4秒,而将恶意软件分类到相应家族平均需要105.9秒。
MaMaDroid[43]利用从调用图获得的抽象函数调用序列来构建行为模型,并使用它来提取特征进行分类。这种方法的一个限制是它可以很容易地被看起来类似于Android、Google或Java包的自定义包[17]规避,另一个限制是由于其大量特征[43],它在分类时需要相当大的内存。
8.3 与MalScan的区别
与IntDroid最相似的工作是我们之前的工作MalScan[54],它将函数调用图视为复杂的社交网络,并对敏感API调用应用基于社交网络的中心性分析来表示图语义进行分类。然而,仅使用敏感API调用的中心性来进行恶意软件检测可能会在良性应用通过调用敏感API表现出与恶意软件类似的行为时导致一些误报。在这种情况下,良性应用中某些敏感API调用的中心性可能与某些恶意软件中的几乎相同。
然而,当我们使用敏感API调用和中心节点之间的亲密度(在第3.2节中定义)来检测恶意软件时,这些良性应用和恶意软件的中心节点是不同的,导致不同应用中相同敏感API调用与中心节点之间的亲密度不同。换句话说,虽然敏感API调用的中心性值相似,但由于中心节点不同,良性应用和恶意应用中API调用和中心节点之间的亲密度可能不同。通过这种方式,我们可以在较低的误报率下检测到更多的恶意软件。
实际上,由于计算敏感API调用和中心节点之间的亲密度,IntDroid的效率低于MalScan。因此,MalScan可以作为第一道防线来过滤大多数恶意软件,然后IntDroid可以作为第二道防线来发现更多恶意软件。通过这种方式,我们可以实现更高效的恶意软件检测并节省更多资源。
9 结论
在本文中,我们提出了一种基于函数调用图中敏感API调用和中心节点之间亲密度分析的新方法来检测Android恶意软件。为了避免重量级图匹配开销,我们将函数调用图视为复杂的社交网络,并进行中心性分析以发掘中心节点。我们实现了一个自动化系统IntDroid,广泛的评估表明我们提出的系统能够在Android恶意软件检测方面保持高准确性和可扩展性。
致谢
我们感谢匿名审稿人提供的富有洞察力的意见,以提高文章的质量。